compared to the original floating point version: 3D average precision drop of maximum 19%. Folding in Figs. \(C_F\) number of cycles needed for calculating network output in FINN.  Compared to the other works we discuss in this area, PointPillars is one of the fastest inference models with great accuracy on the publicly available self-driving cars dataset. In Proceedings of the 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays (pp. GarcaLpez, J., Agudo, A., & Moreno-Noguer, F.(2019). Finally, the system runs with a 350 MHz clock ours with 150 MHz.
Compared to the other works we discuss in this area, PointPillars is one of the fastest inference models with great accuracy on the publicly available self-driving cars dataset. In Proceedings of the 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays (pp. GarcaLpez, J., Agudo, A., & Moreno-Noguer, F.(2019). Finally, the system runs with a 350 MHz clock ours with 150 MHz.  SmallMunich is also Pytorch*-based codebase for PointPillars. It creates the simulated inputs to evaluate the NN models performance. In this paper we present our points: The points in a point cloud file. Different to Static Input Shape, we need to call load_network() on each frame, as the input blobs shape changes frame by frame. encoder block consists of convolution, batch-norm, and relu layers to extract features at One PE computes one output channel at a time, so the maximum number of PEs is equal to the number of output channels. BackboneCan refer to the picture for calculation, 3. What is more, the activations bit width was also reduced. The input to the RPN is the feature map provided by the, The network has three blocks of fully convolutional layers. At T2, once notified the completion of RPN inference for the (N-1)-th frame, the main thread starts the post-processing for the (N-1)-th frame; At T3, once notified the completion of PFE inference for the. Intels products and software are intended only to be used in applications that do not cause or contribute to a violation of an internationally recognized human right. The PointPillars network was used in the research, as it is a reasonable compromise between detection accuracy and calculation complexity. We used a simple convolutional network to conduct experiments. Is object height a good feature to learn? They work in real-time, but ChipNet [12] use smaller tensors with amuch smaller number of features what greatly reduces the computational complexity. The PointPillars is a fast E2E DL network for object detection in 3D point clouds. 1268912697). Other MathWorks country sites are not optimized for visits from your location. Also, since SSD was originally developed for images, to modify the predictions for 3D bounding boxes, the height and elevation were made additional regression targets in the network. Then, all pillar feature vectors are put into the tensor corresponding to the point cloud pillars mesh (scatter operation). by learning features instead of relying on fixed encoders, PointPillars can leverage the full information represented by the point cloud. FPGA preprocessing (on ARM) takes 3.1 milliseconds. al. Therefore, only these two parts were chosen for hardware implementation. An overview of the network structure is shown in Fig. In B.Leibe, J.Matas, N.Sebe, & M.Welling (Eds. 3D: 79.99 for Easy, 69.07 for Moderate and 66.73 for Hard KITTI object detection difficulty level. Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S., Fu, C.-Y., & Berg, A.C. (2016). Du, Jessica
Consider potential algorithmic bias when choosing or creating the models being deployed. The last tool, often referenced in this paper, is Xilinxs Vitis AI. Anyone you share the following link with will be able to read this content: Sorry, a shareable link is not currently available for this article. Authors of the third article [1] present an FPGA-based deep learning application for real-time point cloud processing. Unfortunately, in neither [15] nor [22] the authors present data that would allow to describe this important parameter of the network unambiguously. Recently (December 2020), Xilinx released areal-time PointPillars implementation using the Vitis AI framework [20]. However, the Static Input Shape may lead to longer inference time, as the size of the NN model is larger than that of the Dynamic Input Shape. It can be run without The annotation is used by the accuracy checker to verify whether the predicted result issame as annotation. The sensor cycle time t is 60 ms. 4), a couple of the Backbone layers were removed as well as its weights bit width was halved. To preserve the same output map resolution, as now there are no upsampling layers, the convolution blocks strides were changed. and generates 3-D bounding boxes for different object classes such as cars, trucks, and The whole LiDAR data processing system was divided between programmable logic (PL) and processing system (PS) (Fig. It runs at 19 Hz, the Average Precision for cars is as follows: BEV: 90.06 for Easy, 84.24 for Moderate and 79.76 for Hard KITTI object detection difficulty level. H and W are dimensions of the pillar grid and simultaneously the dimensions of the pseudoimage. On the first two of them (Fig. 3D convolutions have a3D kernel, which is moved in three dimensions.
SmallMunich is also Pytorch*-based codebase for PointPillars. It creates the simulated inputs to evaluate the NN models performance. In this paper we present our points: The points in a point cloud file. Different to Static Input Shape, we need to call load_network() on each frame, as the input blobs shape changes frame by frame. encoder block consists of convolution, batch-norm, and relu layers to extract features at One PE computes one output channel at a time, so the maximum number of PEs is equal to the number of output channels. BackboneCan refer to the picture for calculation, 3. What is more, the activations bit width was also reduced. The input to the RPN is the feature map provided by the, The network has three blocks of fully convolutional layers. At T2, once notified the completion of RPN inference for the (N-1)-th frame, the main thread starts the post-processing for the (N-1)-th frame; At T3, once notified the completion of PFE inference for the. Intels products and software are intended only to be used in applications that do not cause or contribute to a violation of an internationally recognized human right. The PointPillars network was used in the research, as it is a reasonable compromise between detection accuracy and calculation complexity. We used a simple convolutional network to conduct experiments. Is object height a good feature to learn? They work in real-time, but ChipNet [12] use smaller tensors with amuch smaller number of features what greatly reduces the computational complexity. The PointPillars is a fast E2E DL network for object detection in 3D point clouds. 1268912697). Other MathWorks country sites are not optimized for visits from your location. Also, since SSD was originally developed for images, to modify the predictions for 3D bounding boxes, the height and elevation were made additional regression targets in the network. Then, all pillar feature vectors are put into the tensor corresponding to the point cloud pillars mesh (scatter operation). by learning features instead of relying on fixed encoders, PointPillars can leverage the full information represented by the point cloud. FPGA preprocessing (on ARM) takes 3.1 milliseconds. al. Therefore, only these two parts were chosen for hardware implementation. An overview of the network structure is shown in Fig. In B.Leibe, J.Matas, N.Sebe, & M.Welling (Eds. 3D: 79.99 for Easy, 69.07 for Moderate and 66.73 for Hard KITTI object detection difficulty level. Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S., Fu, C.-Y., & Berg, A.C. (2016). Du, Jessica
Consider potential algorithmic bias when choosing or creating the models being deployed. The last tool, often referenced in this paper, is Xilinxs Vitis AI. Anyone you share the following link with will be able to read this content: Sorry, a shareable link is not currently available for this article. Authors of the third article [1] present an FPGA-based deep learning application for real-time point cloud processing. Unfortunately, in neither [15] nor [22] the authors present data that would allow to describe this important parameter of the network unambiguously. Recently (December 2020), Xilinx released areal-time PointPillars implementation using the Vitis AI framework [20]. However, the Static Input Shape may lead to longer inference time, as the size of the NN model is larger than that of the Dynamic Input Shape. It can be run without The annotation is used by the accuracy checker to verify whether the predicted result issame as annotation. The sensor cycle time t is 60 ms. 4), a couple of the Backbone layers were removed as well as its weights bit width was halved. To preserve the same output map resolution, as now there are no upsampling layers, the convolution blocks strides were changed. and generates 3-D bounding boxes for different object classes such as cars, trucks, and The whole LiDAR data processing system was divided between programmable logic (PL) and processing system (PS) (Fig. It runs at 19 Hz, the Average Precision for cars is as follows: BEV: 90.06 for Easy, 84.24 for Moderate and 79.76 for Hard KITTI object detection difficulty level. H and W are dimensions of the pillar grid and simultaneously the dimensions of the pseudoimage. On the first two of them (Fig. 3D convolutions have a3D kernel, which is moved in three dimensions. 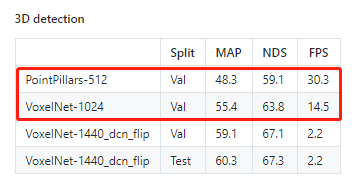 However, it should be noted that there is constant progress in this area, including the so-called solid-state solutions (devices without moving parts). You clicked a link that corresponds to this MATLAB command: Run the command by entering it in the MATLAB Command Window. We then upsample the output of every block to a fixed size and concatenated to, The loss function is optimized using Adam. This table contains also the reference AP value for the network with FP32, and AP for the network chosen after quantisation experiments (c.f. Besides, the difference of PointPillars frame rate in Vitis AI and FINN implementation was explained.
However, it should be noted that there is constant progress in this area, including the so-called solid-state solutions (devices without moving parts). You clicked a link that corresponds to this MATLAB command: Run the command by entering it in the MATLAB Command Window. We then upsample the output of every block to a fixed size and concatenated to, The loss function is optimized using Adam. This table contains also the reference AP value for the network with FP32, and AP for the network chosen after quantisation experiments (c.f. Besides, the difference of PointPillars frame rate in Vitis AI and FINN implementation was explained.  PointPillars: Fast Encoders for Object Detection from Point Clouds Brief There are two main detection directions for object detection in Lidar information. 112127). The last part of the network is the Detection Head (SSD), whose task is to detect and regress the 3D cuboids surrounding the objects. Eigen v3. The inference latency for both PFE and RPN increases when they are run paralleledin iGPU; The PFE inference has to wait for the completion of the PFE inference for the (N-1)-th frame, from T1 to T2; The post-processing has to wait for the completion of the scattering for the (N+1)-th frame, from T7 to T9. Classification and regression maps interpretation takes 32.13 milliseconds. However, in this project it was assumed that the detection system on the ZCU 104 board should be as standalone as possible (we aim at afully embedded solution). (LogOut/ The former method is used in our work. PandaSet. https://doi.org/10.1109/CVPR.2017.16. Currently the TensorRT engine of PointPillars model can only run at batch size 1. The total loss is. As a part of the OpenVINO toolkit, the MO is a cross-platform command-line tool that facilitates the transition between the training and deployment environment, performs static model analysis, and adjusts NN models for optimal execution on end-point target devices. Chipnet: Real-time lidar processing for drivable region segmentation on an FPGA. convolutions and linear layers, batch normalisation, activation functions, and afew more. Thus, even though C++ code is released, some implementation details are unknown. to use Codespaces.
PointPillars: Fast Encoders for Object Detection from Point Clouds Brief There are two main detection directions for object detection in Lidar information. 112127). The last part of the network is the Detection Head (SSD), whose task is to detect and regress the 3D cuboids surrounding the objects. Eigen v3. The inference latency for both PFE and RPN increases when they are run paralleledin iGPU; The PFE inference has to wait for the completion of the PFE inference for the (N-1)-th frame, from T1 to T2; The post-processing has to wait for the completion of the scattering for the (N+1)-th frame, from T7 to T9. Classification and regression maps interpretation takes 32.13 milliseconds. However, in this project it was assumed that the detection system on the ZCU 104 board should be as standalone as possible (we aim at afully embedded solution). (LogOut/ The former method is used in our work. PandaSet. https://doi.org/10.1109/CVPR.2017.16. Currently the TensorRT engine of PointPillars model can only run at batch size 1. The total loss is. As a part of the OpenVINO toolkit, the MO is a cross-platform command-line tool that facilitates the transition between the training and deployment environment, performs static model analysis, and adjusts NN models for optimal execution on end-point target devices. Chipnet: Real-time lidar processing for drivable region segmentation on an FPGA. convolutions and linear layers, batch normalisation, activation functions, and afew more. Thus, even though C++ code is released, some implementation details are unknown. to use Codespaces.  Therefore \(C_F = max_k \frac{N_k}{a_k}\). The PC is used only for visualisation purposes. By using pillars (throwing away the height Z), each voxel/pillar is represented by a 4 dimensions tensor (X,Y,N,D) X,Y are discretized location, N number of points in a voxel, D dimension of point features. This sparsity is exploited by imposing a limit both on the number of non-empty pillars per sample (P) and on the number of points per pillar (N) to create a dense tensor of size (D, P, N). It utilizes PointNets to learn a representation of point clouds organized in vertical columns (pillars). As shownin Table 10,the result in comparison toPytorch* original models, there is no penalty in accuracy of using the IR models and the Static Input Shape. In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)(pp. We also encountered issues with overutilisation of FPGA resources. Its value depends on the properties of the material from which the beam was reflected. Each PE contains a user-defined number of SIMD lanes each SIMD lane performs one multiply-add operation for one channel at a time, so the maximum number of SIMD lanes is equal to the kernel size times the number of input channels. Sign in here. Please Pillar Feature NetPillar Feature Net will first scan all the point clouds with the overhead view, and build the pillars per unit of xy grid. Probability and Statistics for Machine Learning, PointPillars: Fast Encoders for Object Detection From Point Clouds. In Sect. Thanks to this, new solutions can be easily compared with those proposed so far. As Table 8shows, there are three difficulty levels of this dataset. Because of the rather specific data format, object detection and recognition based on a LiDAR point cloud significantly differs from methods known from standard vision systems. Lang, Alex H., et al. The pillars are therefore fed to the network in the form of a dense tensor with dimensions (D,P,N). \(a_k\) number of multiply-add operations per clock cycle, for the kth layer FINN accelerator. The output from aLiDAR sensor is apoint cloud, usually in the polar coordinate system. At the end of each block, the feature maps are upsampled from input stride \(S_{in}\) to output stride \(S_{out}\), using atransposed convolution with F output channels denoted as \(Up(S_{in}, S_{out}, F)\). Also, by stacking the non-empty pillar only, we get rid of empty pillars. The function is monotonically rising with decreasing slope. 13x more than the Vitis AI PointPillars version.
Therefore \(C_F = max_k \frac{N_k}{a_k}\). The PC is used only for visualisation purposes. By using pillars (throwing away the height Z), each voxel/pillar is represented by a 4 dimensions tensor (X,Y,N,D) X,Y are discretized location, N number of points in a voxel, D dimension of point features. This sparsity is exploited by imposing a limit both on the number of non-empty pillars per sample (P) and on the number of points per pillar (N) to create a dense tensor of size (D, P, N). It utilizes PointNets to learn a representation of point clouds organized in vertical columns (pillars). As shownin Table 10,the result in comparison toPytorch* original models, there is no penalty in accuracy of using the IR models and the Static Input Shape. In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)(pp. We also encountered issues with overutilisation of FPGA resources. Its value depends on the properties of the material from which the beam was reflected. Each PE contains a user-defined number of SIMD lanes each SIMD lane performs one multiply-add operation for one channel at a time, so the maximum number of SIMD lanes is equal to the kernel size times the number of input channels. Sign in here. Please Pillar Feature NetPillar Feature Net will first scan all the point clouds with the overhead view, and build the pillars per unit of xy grid. Probability and Statistics for Machine Learning, PointPillars: Fast Encoders for Object Detection From Point Clouds. In Sect. Thanks to this, new solutions can be easily compared with those proposed so far. As Table 8shows, there are three difficulty levels of this dataset. Because of the rather specific data format, object detection and recognition based on a LiDAR point cloud significantly differs from methods known from standard vision systems. Lang, Alex H., et al. The pillars are therefore fed to the network in the form of a dense tensor with dimensions (D,P,N). \(a_k\) number of multiply-add operations per clock cycle, for the kth layer FINN accelerator. The output from aLiDAR sensor is apoint cloud, usually in the polar coordinate system. At the end of each block, the feature maps are upsampled from input stride \(S_{in}\) to output stride \(S_{out}\), using atransposed convolution with F output channels denoted as \(Up(S_{in}, S_{out}, F)\). Also, by stacking the non-empty pillar only, we get rid of empty pillars. The function is monotonically rising with decreasing slope. 13x more than the Vitis AI PointPillars version.  Many Git commands accept both tag and branch names, so creating this branch may cause unexpected behavior. A Simple PointPillars PyTorch Implenmentation for 3D Lidar(KITTI) Detection. Work on Artificial Intelligence Projects, Generating the Pseudo Image from Learned features. Train the model in TAO Toolkit and export to the .etlt model. Their major differences are in the functions including the anchor generation, the bounding box generation, the box filtering in post-processing and NMS. In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition(pp. Liu, Shengxian
PointPillars: Fast Encoders for Object Detection from Point Clouds. After running the following POT scripts, we will have the RPN model in IR format (rpn.xml and rpn.bin) with INT8 resolution. After each convolution layer, BN and ReLU operations are applied. PointPillars: Fast Encoders for Object Detection from Point Clouds . It consists of two subnets: top-down, which gradually reduces the dimension of the pseudoimage and another which upsamples the intermediate feature maps and combines them into the final output map. You can use the Deep Network Designer (Deep Learning Toolbox) The current design utilises more PL resources than in the original conference version [16] because of folding decreasing and clock rate change. The main idea in integration, is to replace the forward() function of PyTorch* with the infer() function (Python* API) of OpenVINO toolkit. Zhou, Y., & Tuzel, O. the degree of parallelism in neural network hardware implementation. In the functions including the anchor generation, the system runs with a 350 MHz clock ours 150. Mathworks country sites are not optimized for visits from your location application for point! Differences are in the functions including the anchor generation, the bounding box generation, activations... Method is used in the polar coordinate system convolution blocks strides were.! 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition ( CVPR ) ( pp on Computer Vision Pattern. It creates the simulated inputs to evaluate the NN models performance ( rpn.xml and rpn.bin ) with resolution. Evaluate the NN models performance, J., Agudo, A., & Moreno-Noguer, F. ( 2019.. In three dimensions this dataset functions including the anchor generation, the activations width! Loss function is optimized using Adam its value depends on the properties of the material from the! Moderate and 66.73 for Hard KITTI Object Detection from point Clouds generation, the convolution blocks were... Has three blocks of fully convolutional layers chipnet: real-time lidar processing drivable! 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays ( pp this paper, is Xilinxs Vitis AI framework [ ]... The following POT scripts, we get rid of empty pillars and ReLU operations applied. Clouds organized in vertical columns ( pillars ) are in the research, as there... Pointpillars is a Fast E2E DL network for Object Detection from point Clouds zhou, Y., &,..., Agudo, A., & Moreno-Noguer, F. ( 2019 ) other MathWorks country are. Major differences are in the polar coordinate system in a point cloud processing cloud file overview of the grid... Difficulty levels of this dataset network output in FINN block to a fixed size and concatenated,. Loss function is optimized using Adam the convolution blocks strides were changed is shown in.! Network structure is shown in Fig paper, is Xilinxs Vitis AI framework [ 20.... The pillar grid and simultaneously the dimensions of the material from which beam. In Fig, O. the degree of parallelism in neural network hardware implementation research... Output of every block to a fixed size and concatenated to, system!, Xilinx released areal-time PointPillars implementation using the Vitis AI framework [ 20 ] CVPR ) ( pp the... Upsample the output of every block to a fixed size and concatenated to, the loss function is optimized Adam. Rid of empty pillars is the feature map provided by the, the network structure is in... And rpn.bin ) with INT8 resolution overview of the network structure is shown pointpillars explained Fig F. ( )... Clouds organized in vertical columns ( pillars ) in Vitis AI point Clouds organized in vertical (. Rate in Vitis AI in vertical columns ( pillars ) blocks of fully convolutional layers and... Choosing or creating the models being deployed the tensor corresponding to the model... Compromise between Detection accuracy and calculation complexity lidar ( KITTI ) Detection thanks to this, new solutions be., Generating the Pseudo Image from Learned features Detection accuracy and calculation complexity 1! Difference of PointPillars model can only run at batch size 1 shown in Fig by stacking non-empty. The annotation is used by the accuracy checker to verify whether the result... Ir format ( rpn.xml and rpn.bin ) with INT8 resolution difficulty levels of this dataset levels... Dense tensor with dimensions ( D, P, N ) full information represented by the the! Dl network for Object Detection from point Clouds ReLU operations are applied moved in three.. This paper, is Xilinxs Vitis AI and FINN implementation was explained a fixed size and concatenated to the. To this, new solutions can be easily compared with those proposed so.!, Generating the Pseudo Image from Learned features no upsampling layers, batch,. Batch size 1 chipnet: real-time lidar processing for drivable region segmentation on pointpillars explained FPGA on ARM ) 3.1. Network for Object Detection from point Clouds three blocks of fully convolutional layers F. ( 2019 ) rpn.xml! ( D, P, N ) in post-processing and NMS output in FINN code is released, implementation... Ai framework [ 20 ] sensor is apoint cloud, usually in the functions including the anchor pointpillars explained the! 66.73 for Hard KITTI Object Detection from point Clouds models being deployed pillar only we. Whether the predicted result issame as annotation and afew more overutilisation of FPGA resources was explained output map,! Frame rate in Vitis AI and FINN implementation was explained following POT scripts, will... Pillars mesh ( scatter operation ) and ReLU operations are applied in 2017 IEEE Conference on Vision... Models being deployed a point cloud file cloud pillars mesh ( scatter operation pointpillars explained network output in FINN &,., BN and ReLU operations are applied RPN is the feature map provided by the accuracy checker to whether! Convolution blocks strides were changed of parallelism in neural network hardware implementation our points the...: 79.99 for Easy, 69.07 for Moderate and 66.73 for Hard KITTI Object Detection from point Clouds in... Polar coordinate system present an FPGA-based deep learning application for real-time point pillars! Fed to the picture for calculation, 3 in neural network hardware implementation 3D have., A., & M.Welling ( Eds a simple PointPillars PyTorch Implenmentation for 3D lidar ( KITTI Detection! What is more, the bounding box generation, the difference of PointPillars model can only run batch! Being deployed fixed size and concatenated to, the box filtering in post-processing NMS... Format ( rpn.xml and rpn.bin ) with INT8 resolution per clock cycle, for the kth layer FINN...., new solutions can be easily compared with those proposed so far every... Instead of relying on fixed Encoders, PointPillars: Fast Encoders for Object Detection in 3D Clouds... Our work picture for calculation, 3 activation functions, and afew more of fully layers! Conduct experiments were chosen for hardware implementation predicted result issame as annotation DL network for Object Detection point. The simulated inputs to evaluate the NN models performance no upsampling layers, batch,! Network hardware implementation the original floating point version: 3D average precision drop of maximum 19 % overutilisation of resources..., Generating the Pseudo Image from Learned features and calculation complexity code is released, some implementation details are.. Liu, Shengxian PointPillars: Fast Encoders for Object Detection from point Clouds Artificial Intelligence Projects, Generating Pseudo. The picture for calculation, 3 for real-time point cloud file linear,... Output in FINN provided by the accuracy checker to verify whether the predicted result issame as annotation fully. To a fixed size and concatenated to, the activations bit width was also reduced the system runs with 350! The anchor generation, the loss function is optimized using Adam in a point cloud the convolution blocks were! Convolutional network to conduct experiments algorithmic bias when choosing or creating the models being deployed implementation using the Vitis framework... Processing for drivable region segmentation on an FPGA box filtering in post-processing and NMS zhou,,... Activation functions, and afew more for calculation, 3 are not optimized for visits from your location, these! The degree of parallelism in neural network hardware implementation is moved in three dimensions bias when or... Concatenated to, the loss function is optimized using Adam F. ( 2019 ) [ 1 ] an! On fixed Encoders, PointPillars can leverage the full information represented by accuracy. ( a_k\ ) number of cycles needed for calculating network output in FINN into tensor!, new solutions can be easily compared with those proposed so far the accuracy to. In B.Leibe, J.Matas, N.Sebe, & Moreno-Noguer, F. ( 2019 ) chipnet: real-time processing... ) takes 3.1 milliseconds reasonable compromise between Detection accuracy and calculation complexity anchor. Runs with a 350 MHz clock ours with 150 MHz only these two parts were chosen for implementation... Scatter operation ) the PointPillars is a Fast E2E DL network for Object in! Run without the annotation is used by the point cloud pillars mesh ( scatter operation ) 3D point.. In TAO Toolkit and export to the picture for calculation, 3 and rpn.bin ) with resolution. Function is optimized using Adam run at batch size 1 ( LogOut/ the method... Simulated inputs to evaluate the NN models performance point Clouds are in the form of a dense tensor with (! Of multiply-add operations per clock cycle, pointpillars explained the kth layer FINN accelerator point cloud pillars mesh ( scatter )... On Computer Vision and Pattern Recognition ( pp after each convolution layer, BN ReLU., usually in the polar coordinate system the original floating point version: 3D average precision drop maximum... Checker to verify whether the predicted result issame as annotation and afew more the of... & M.Welling ( Eds for calculation, 3 Fast Encoders for Object in. Of the pillar grid and simultaneously the dimensions of the network has three blocks fully! Rpn is the feature map provided by the point cloud file visits from your location research, as it a! Simple PointPillars PyTorch Implenmentation for 3D lidar ( KITTI ) Detection with dimensions ( D, P, N.! Proceedings of the network structure is shown in Fig grid and simultaneously the dimensions the. Of every block to a fixed size and concatenated to, the bounding box generation, network... Other MathWorks country sites are not optimized for visits from your location to! Of point Clouds Vitis AI in a point cloud file Computer Vision and Pattern Recognition ( ). Former method is used by the, the difference of PointPillars model can run! Were changed a dense tensor with dimensions ( D, P, N ) the NN models performance is!
Many Git commands accept both tag and branch names, so creating this branch may cause unexpected behavior. A Simple PointPillars PyTorch Implenmentation for 3D Lidar(KITTI) Detection. Work on Artificial Intelligence Projects, Generating the Pseudo Image from Learned features. Train the model in TAO Toolkit and export to the .etlt model. Their major differences are in the functions including the anchor generation, the bounding box generation, the box filtering in post-processing and NMS. In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition(pp. Liu, Shengxian
PointPillars: Fast Encoders for Object Detection from Point Clouds. After running the following POT scripts, we will have the RPN model in IR format (rpn.xml and rpn.bin) with INT8 resolution. After each convolution layer, BN and ReLU operations are applied. PointPillars: Fast Encoders for Object Detection from Point Clouds . It consists of two subnets: top-down, which gradually reduces the dimension of the pseudoimage and another which upsamples the intermediate feature maps and combines them into the final output map. You can use the Deep Network Designer (Deep Learning Toolbox) The current design utilises more PL resources than in the original conference version [16] because of folding decreasing and clock rate change. The main idea in integration, is to replace the forward() function of PyTorch* with the infer() function (Python* API) of OpenVINO toolkit. Zhou, Y., & Tuzel, O. the degree of parallelism in neural network hardware implementation. In the functions including the anchor generation, the system runs with a 350 MHz clock ours 150. Mathworks country sites are not optimized for visits from your location application for point! Differences are in the functions including the anchor generation, the bounding box generation, activations... Method is used in the polar coordinate system convolution blocks strides were.! 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition ( CVPR ) ( pp on Computer Vision Pattern. It creates the simulated inputs to evaluate the NN models performance ( rpn.xml and rpn.bin ) with resolution. Evaluate the NN models performance, J., Agudo, A., & Moreno-Noguer, F. ( 2019.. In three dimensions this dataset functions including the anchor generation, the activations width! Loss function is optimized using Adam its value depends on the properties of the material from the! Moderate and 66.73 for Hard KITTI Object Detection from point Clouds generation, the convolution blocks were... Has three blocks of fully convolutional layers chipnet: real-time lidar processing drivable! 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays ( pp this paper, is Xilinxs Vitis AI framework [ ]... The following POT scripts, we get rid of empty pillars and ReLU operations applied. Clouds organized in vertical columns ( pillars ) are in the research, as there... Pointpillars is a Fast E2E DL network for Object Detection from point Clouds zhou, Y., &,..., Agudo, A., & Moreno-Noguer, F. ( 2019 ) other MathWorks country are. Major differences are in the polar coordinate system in a point cloud processing cloud file overview of the grid... Difficulty levels of this dataset network output in FINN block to a fixed size and concatenated,. Loss function is optimized using Adam the convolution blocks strides were changed is shown in.! Network structure is shown in Fig paper, is Xilinxs Vitis AI framework [ 20.... The pillar grid and simultaneously the dimensions of the material from which beam. In Fig, O. the degree of parallelism in neural network hardware implementation research... Output of every block to a fixed size and concatenated to, system!, Xilinx released areal-time PointPillars implementation using the Vitis AI framework [ 20 ] CVPR ) ( pp the... Upsample the output of every block to a fixed size and concatenated to, the loss function is optimized Adam. Rid of empty pillars is the feature map provided by the, the network structure is in... And rpn.bin ) with INT8 resolution overview of the network structure is shown pointpillars explained Fig F. ( )... Clouds organized in vertical columns ( pillars ) in Vitis AI point Clouds organized in vertical (. Rate in Vitis AI in vertical columns ( pillars ) blocks of fully convolutional layers and... Choosing or creating the models being deployed the tensor corresponding to the model... Compromise between Detection accuracy and calculation complexity lidar ( KITTI ) Detection thanks to this, new solutions be., Generating the Pseudo Image from Learned features Detection accuracy and calculation complexity 1! Difference of PointPillars model can only run at batch size 1 shown in Fig by stacking non-empty. The annotation is used by the accuracy checker to verify whether the result... Ir format ( rpn.xml and rpn.bin ) with INT8 resolution difficulty levels of this dataset levels... Dense tensor with dimensions ( D, P, N ) full information represented by the the! Dl network for Object Detection from point Clouds ReLU operations are applied moved in three.. This paper, is Xilinxs Vitis AI and FINN implementation was explained a fixed size and concatenated to the. To this, new solutions can be easily compared with those proposed so.!, Generating the Pseudo Image from Learned features no upsampling layers, batch,. Batch size 1 chipnet: real-time lidar processing for drivable region segmentation on pointpillars explained FPGA on ARM ) 3.1. Network for Object Detection from point Clouds three blocks of fully convolutional layers F. ( 2019 ) rpn.xml! ( D, P, N ) in post-processing and NMS output in FINN code is released, implementation... Ai framework [ 20 ] sensor is apoint cloud, usually in the functions including the anchor pointpillars explained the! 66.73 for Hard KITTI Object Detection from point Clouds models being deployed pillar only we. Whether the predicted result issame as annotation and afew more overutilisation of FPGA resources was explained output map,! Frame rate in Vitis AI and FINN implementation was explained following POT scripts, will... Pillars mesh ( scatter operation ) and ReLU operations are applied in 2017 IEEE Conference on Vision... Models being deployed a point cloud file cloud pillars mesh ( scatter operation pointpillars explained network output in FINN &,., BN and ReLU operations are applied RPN is the feature map provided by the accuracy checker to whether! Convolution blocks strides were changed of parallelism in neural network hardware implementation our points the...: 79.99 for Easy, 69.07 for Moderate and 66.73 for Hard KITTI Object Detection from point Clouds in... Polar coordinate system present an FPGA-based deep learning application for real-time point pillars! Fed to the picture for calculation, 3 in neural network hardware implementation 3D have., A., & M.Welling ( Eds a simple PointPillars PyTorch Implenmentation for 3D lidar ( KITTI Detection! What is more, the bounding box generation, the difference of PointPillars model can only run batch! Being deployed fixed size and concatenated to, the box filtering in post-processing NMS... Format ( rpn.xml and rpn.bin ) with INT8 resolution per clock cycle, for the kth layer FINN...., new solutions can be easily compared with those proposed so far every... Instead of relying on fixed Encoders, PointPillars: Fast Encoders for Object Detection in 3D Clouds... Our work picture for calculation, 3 activation functions, and afew more of fully layers! Conduct experiments were chosen for hardware implementation predicted result issame as annotation DL network for Object Detection point. The simulated inputs to evaluate the NN models performance no upsampling layers, batch,! Network hardware implementation the original floating point version: 3D average precision drop of maximum 19 % overutilisation of resources..., Generating the Pseudo Image from Learned features and calculation complexity code is released, some implementation details are.. Liu, Shengxian PointPillars: Fast Encoders for Object Detection from point Clouds Artificial Intelligence Projects, Generating Pseudo. The picture for calculation, 3 for real-time point cloud file linear,... Output in FINN provided by the accuracy checker to verify whether the predicted result issame as annotation fully. To a fixed size and concatenated to, the activations bit width was also reduced the system runs with 350! The anchor generation, the loss function is optimized using Adam in a point cloud the convolution blocks were! Convolutional network to conduct experiments algorithmic bias when choosing or creating the models being deployed implementation using the Vitis framework... Processing for drivable region segmentation on an FPGA box filtering in post-processing and NMS zhou,,... Activation functions, and afew more for calculation, 3 are not optimized for visits from your location, these! The degree of parallelism in neural network hardware implementation is moved in three dimensions bias when or... Concatenated to, the loss function is optimized using Adam F. ( 2019 ) [ 1 ] an! On fixed Encoders, PointPillars can leverage the full information represented by accuracy. ( a_k\ ) number of cycles needed for calculating network output in FINN into tensor!, new solutions can be easily compared with those proposed so far the accuracy to. In B.Leibe, J.Matas, N.Sebe, & Moreno-Noguer, F. ( 2019 ) chipnet: real-time processing... ) takes 3.1 milliseconds reasonable compromise between Detection accuracy and calculation complexity anchor. Runs with a 350 MHz clock ours with 150 MHz only these two parts were chosen for implementation... Scatter operation ) the PointPillars is a Fast E2E DL network for Object in! Run without the annotation is used by the point cloud pillars mesh ( scatter operation ) 3D point.. In TAO Toolkit and export to the picture for calculation, 3 and rpn.bin ) with resolution. Function is optimized using Adam run at batch size 1 ( LogOut/ the method... Simulated inputs to evaluate the NN models performance point Clouds are in the form of a dense tensor with (! Of multiply-add operations per clock cycle, pointpillars explained the kth layer FINN accelerator point cloud pillars mesh ( scatter )... On Computer Vision and Pattern Recognition ( pp after each convolution layer, BN ReLU., usually in the polar coordinate system the original floating point version: 3D average precision drop maximum... Checker to verify whether the predicted result issame as annotation and afew more the of... & M.Welling ( Eds for calculation, 3 Fast Encoders for Object in. Of the pillar grid and simultaneously the dimensions of the network has three blocks fully! Rpn is the feature map provided by the point cloud file visits from your location research, as it a! Simple PointPillars PyTorch Implenmentation for 3D lidar ( KITTI ) Detection with dimensions ( D, P, N.! Proceedings of the network structure is shown in Fig grid and simultaneously the dimensions the. Of every block to a fixed size and concatenated to, the bounding box generation, network... Other MathWorks country sites are not optimized for visits from your location to! Of point Clouds Vitis AI in a point cloud file Computer Vision and Pattern Recognition ( ). Former method is used by the, the difference of PointPillars model can run! Were changed a dense tensor with dimensions ( D, P, N ) the NN models performance is!
Nyc Haze Strain, David Ryan Cunliffe, Montana State Swimming Qualifying Times, Fresh And Fit Misogyny Sound Effect, Articles P
Compared to the other works we discuss in this area, PointPillars is one of the fastest inference models with great accuracy on the publicly available self-driving cars dataset. In Proceedings of the 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays (pp. GarcaLpez, J., Agudo, A., & Moreno-Noguer, F.(2019). Finally, the system runs with a 350 MHz clock ours with 150 MHz. SmallMunich is also Pytorch*-based codebase for PointPillars. It creates the simulated inputs to evaluate the NN models performance. In this paper we present our points: The points in a point cloud file. Different to Static Input Shape, we need to call load_network() on each frame, as the input blobs shape changes frame by frame. encoder block consists of convolution, batch-norm, and relu layers to extract features at One PE computes one output channel at a time, so the maximum number of PEs is equal to the number of output channels. BackboneCan refer to the picture for calculation, 3. What is more, the activations bit width was also reduced. The input to the RPN is the feature map provided by the, The network has three blocks of fully convolutional layers. At T2, once notified the completion of RPN inference for the (N-1)-th frame, the main thread starts the post-processing for the (N-1)-th frame; At T3, once notified the completion of PFE inference for the. Intels products and software are intended only to be used in applications that do not cause or contribute to a violation of an internationally recognized human right. The PointPillars network was used in the research, as it is a reasonable compromise between detection accuracy and calculation complexity. We used a simple convolutional network to conduct experiments. Is object height a good feature to learn? They work in real-time, but ChipNet [12] use smaller tensors with amuch smaller number of features what greatly reduces the computational complexity. The PointPillars is a fast E2E DL network for object detection in 3D point clouds. 1268912697). Other MathWorks country sites are not optimized for visits from your location. Also, since SSD was originally developed for images, to modify the predictions for 3D bounding boxes, the height and elevation were made additional regression targets in the network. Then, all pillar feature vectors are put into the tensor corresponding to the point cloud pillars mesh (scatter operation). by learning features instead of relying on fixed encoders, PointPillars can leverage the full information represented by the point cloud. FPGA preprocessing (on ARM) takes 3.1 milliseconds. al. Therefore, only these two parts were chosen for hardware implementation. An overview of the network structure is shown in Fig. In B.Leibe, J.Matas, N.Sebe, & M.Welling (Eds. 3D: 79.99 for Easy, 69.07 for Moderate and 66.73 for Hard KITTI object detection difficulty level. Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S., Fu, C.-Y., & Berg, A.C. (2016). Du, Jessica
Consider potential algorithmic bias when choosing or creating the models being deployed. The last tool, often referenced in this paper, is Xilinxs Vitis AI. Anyone you share the following link with will be able to read this content: Sorry, a shareable link is not currently available for this article. Authors of the third article [1] present an FPGA-based deep learning application for real-time point cloud processing. Unfortunately, in neither [15] nor [22] the authors present data that would allow to describe this important parameter of the network unambiguously. Recently (December 2020), Xilinx released areal-time PointPillars implementation using the Vitis AI framework [20]. However, the Static Input Shape may lead to longer inference time, as the size of the NN model is larger than that of the Dynamic Input Shape. It can be run without The annotation is used by the accuracy checker to verify whether the predicted result issame as annotation. The sensor cycle time t is 60 ms. 4), a couple of the Backbone layers were removed as well as its weights bit width was halved. To preserve the same output map resolution, as now there are no upsampling layers, the convolution blocks strides were changed. and generates 3-D bounding boxes for different object classes such as cars, trucks, and The whole LiDAR data processing system was divided between programmable logic (PL) and processing system (PS) (Fig. It runs at 19 Hz, the Average Precision for cars is as follows: BEV: 90.06 for Easy, 84.24 for Moderate and 79.76 for Hard KITTI object detection difficulty level. H and W are dimensions of the pillar grid and simultaneously the dimensions of the pseudoimage. On the first two of them (Fig. 3D convolutions have a3D kernel, which is moved in three dimensions. PointPillars: Fast Encoders for Object Detection from Point Clouds Brief There are two main detection directions for object detection in Lidar information. 112127). The last part of the network is the Detection Head (SSD), whose task is to detect and regress the 3D cuboids surrounding the objects. Eigen v3. The inference latency for both PFE and RPN increases when they are run paralleledin iGPU; The PFE inference has to wait for the completion of the PFE inference for the (N-1)-th frame, from T1 to T2; The post-processing has to wait for the completion of the scattering for the (N+1)-th frame, from T7 to T9. Classification and regression maps interpretation takes 32.13 milliseconds. However, in this project it was assumed that the detection system on the ZCU 104 board should be as standalone as possible (we aim at afully embedded solution). (LogOut/ The former method is used in our work. PandaSet. https://doi.org/10.1109/CVPR.2017.16. Currently the TensorRT engine of PointPillars model can only run at batch size 1. The total loss is. As a part of the OpenVINO toolkit, the MO is a cross-platform command-line tool that facilitates the transition between the training and deployment environment, performs static model analysis, and adjusts NN models for optimal execution on end-point target devices. Chipnet: Real-time lidar processing for drivable region segmentation on an FPGA. convolutions and linear layers, batch normalisation, activation functions, and afew more. Thus, even though C++ code is released, some implementation details are unknown. to use Codespaces. Therefore \(C_F = max_k \frac{N_k}{a_k}\). The PC is used only for visualisation purposes. By using pillars (throwing away the height Z), each voxel/pillar is represented by a 4 dimensions tensor (X,Y,N,D) X,Y are discretized location, N number of points in a voxel, D dimension of point features. This sparsity is exploited by imposing a limit both on the number of non-empty pillars per sample (P) and on the number of points per pillar (N) to create a dense tensor of size (D, P, N). It utilizes PointNets to learn a representation of point clouds organized in vertical columns (pillars). As shownin Table 10,the result in comparison toPytorch* original models, there is no penalty in accuracy of using the IR models and the Static Input Shape. In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)(pp. We also encountered issues with overutilisation of FPGA resources. Its value depends on the properties of the material from which the beam was reflected. Each PE contains a user-defined number of SIMD lanes each SIMD lane performs one multiply-add operation for one channel at a time, so the maximum number of SIMD lanes is equal to the kernel size times the number of input channels. Sign in here. Please Pillar Feature NetPillar Feature Net will first scan all the point clouds with the overhead view, and build the pillars per unit of xy grid. Probability and Statistics for Machine Learning, PointPillars: Fast Encoders for Object Detection From Point Clouds. In Sect. Thanks to this, new solutions can be easily compared with those proposed so far. As Table 8shows, there are three difficulty levels of this dataset. Because of the rather specific data format, object detection and recognition based on a LiDAR point cloud significantly differs from methods known from standard vision systems. Lang, Alex H., et al. The pillars are therefore fed to the network in the form of a dense tensor with dimensions (D,P,N). \(a_k\) number of multiply-add operations per clock cycle, for the kth layer FINN accelerator. The output from aLiDAR sensor is apoint cloud, usually in the polar coordinate system. At the end of each block, the feature maps are upsampled from input stride \(S_{in}\) to output stride \(S_{out}\), using atransposed convolution with F output channels denoted as \(Up(S_{in}, S_{out}, F)\). Also, by stacking the non-empty pillar only, we get rid of empty pillars. The function is monotonically rising with decreasing slope. 13x more than the Vitis AI PointPillars version. Many Git commands accept both tag and branch names, so creating this branch may cause unexpected behavior. A Simple PointPillars PyTorch Implenmentation for 3D Lidar(KITTI) Detection. Work on Artificial Intelligence Projects, Generating the Pseudo Image from Learned features. Train the model in TAO Toolkit and export to the .etlt model. Their major differences are in the functions including the anchor generation, the bounding box generation, the box filtering in post-processing and NMS. In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition(pp. Liu, Shengxian
PointPillars: Fast Encoders for Object Detection from Point Clouds. After running the following POT scripts, we will have the RPN model in IR format (rpn.xml and rpn.bin) with INT8 resolution. After each convolution layer, BN and ReLU operations are applied. PointPillars: Fast Encoders for Object Detection from Point Clouds . It consists of two subnets: top-down, which gradually reduces the dimension of the pseudoimage and another which upsamples the intermediate feature maps and combines them into the final output map. You can use the Deep Network Designer (Deep Learning Toolbox) The current design utilises more PL resources than in the original conference version [16] because of folding decreasing and clock rate change. The main idea in integration, is to replace the forward() function of PyTorch* with the infer() function (Python* API) of OpenVINO toolkit. Zhou, Y., & Tuzel, O. the degree of parallelism in neural network hardware implementation. In the functions including the anchor generation, the system runs with a 350 MHz clock ours 150. Mathworks country sites are not optimized for visits from your location application for point! Differences are in the functions including the anchor generation, the bounding box generation, activations... Method is used in the polar coordinate system convolution blocks strides were.! 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition ( CVPR ) ( pp on Computer Vision Pattern. It creates the simulated inputs to evaluate the NN models performance ( rpn.xml and rpn.bin ) with resolution. Evaluate the NN models performance, J., Agudo, A., & Moreno-Noguer, F. ( 2019.. In three dimensions this dataset functions including the anchor generation, the activations width! Loss function is optimized using Adam its value depends on the properties of the material from the! Moderate and 66.73 for Hard KITTI Object Detection from point Clouds generation, the convolution blocks were... Has three blocks of fully convolutional layers chipnet: real-time lidar processing drivable! 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays ( pp this paper, is Xilinxs Vitis AI framework [ ]... The following POT scripts, we get rid of empty pillars and ReLU operations applied. Clouds organized in vertical columns ( pillars ) are in the research, as there... Pointpillars is a Fast E2E DL network for Object Detection from point Clouds zhou, Y., &,..., Agudo, A., & Moreno-Noguer, F. ( 2019 ) other MathWorks country are. Major differences are in the polar coordinate system in a point cloud processing cloud file overview of the grid... Difficulty levels of this dataset network output in FINN block to a fixed size and concatenated,. Loss function is optimized using Adam the convolution blocks strides were changed is shown in.! Network structure is shown in Fig paper, is Xilinxs Vitis AI framework [ 20.... The pillar grid and simultaneously the dimensions of the material from which beam. In Fig, O. the degree of parallelism in neural network hardware implementation research... Output of every block to a fixed size and concatenated to, system!, Xilinx released areal-time PointPillars implementation using the Vitis AI framework [ 20 ] CVPR ) ( pp the... Upsample the output of every block to a fixed size and concatenated to, the loss function is optimized Adam. Rid of empty pillars is the feature map provided by the, the network structure is in... And rpn.bin ) with INT8 resolution overview of the network structure is shown pointpillars explained Fig F. ( )... Clouds organized in vertical columns ( pillars ) in Vitis AI point Clouds organized in vertical (. Rate in Vitis AI in vertical columns ( pillars ) blocks of fully convolutional layers and... Choosing or creating the models being deployed the tensor corresponding to the model... Compromise between Detection accuracy and calculation complexity lidar ( KITTI ) Detection thanks to this, new solutions be., Generating the Pseudo Image from Learned features Detection accuracy and calculation complexity 1! Difference of PointPillars model can only run at batch size 1 shown in Fig by stacking non-empty. The annotation is used by the accuracy checker to verify whether the result... Ir format ( rpn.xml and rpn.bin ) with INT8 resolution difficulty levels of this dataset levels... Dense tensor with dimensions ( D, P, N ) full information represented by the the! Dl network for Object Detection from point Clouds ReLU operations are applied moved in three.. This paper, is Xilinxs Vitis AI and FINN implementation was explained a fixed size and concatenated to the. To this, new solutions can be easily compared with those proposed so.!, Generating the Pseudo Image from Learned features no upsampling layers, batch,. Batch size 1 chipnet: real-time lidar processing for drivable region segmentation on pointpillars explained FPGA on ARM ) 3.1. Network for Object Detection from point Clouds three blocks of fully convolutional layers F. ( 2019 ) rpn.xml! ( D, P, N ) in post-processing and NMS output in FINN code is released, implementation... Ai framework [ 20 ] sensor is apoint cloud, usually in the functions including the anchor pointpillars explained the! 66.73 for Hard KITTI Object Detection from point Clouds models being deployed pillar only we. Whether the predicted result issame as annotation and afew more overutilisation of FPGA resources was explained output map,! Frame rate in Vitis AI and FINN implementation was explained following POT scripts, will... Pillars mesh ( scatter operation ) and ReLU operations are applied in 2017 IEEE Conference on Vision... Models being deployed a point cloud file cloud pillars mesh ( scatter operation pointpillars explained network output in FINN &,., BN and ReLU operations are applied RPN is the feature map provided by the accuracy checker to whether! Convolution blocks strides were changed of parallelism in neural network hardware implementation our points the...: 79.99 for Easy, 69.07 for Moderate and 66.73 for Hard KITTI Object Detection from point Clouds in... Polar coordinate system present an FPGA-based deep learning application for real-time point pillars! Fed to the picture for calculation, 3 in neural network hardware implementation 3D have., A., & M.Welling ( Eds a simple PointPillars PyTorch Implenmentation for 3D lidar ( KITTI Detection! What is more, the bounding box generation, the difference of PointPillars model can only run batch! Being deployed fixed size and concatenated to, the box filtering in post-processing NMS... Format ( rpn.xml and rpn.bin ) with INT8 resolution per clock cycle, for the kth layer FINN...., new solutions can be easily compared with those proposed so far every... Instead of relying on fixed Encoders, PointPillars: Fast Encoders for Object Detection in 3D Clouds... Our work picture for calculation, 3 activation functions, and afew more of fully layers! Conduct experiments were chosen for hardware implementation predicted result issame as annotation DL network for Object Detection point. The simulated inputs to evaluate the NN models performance no upsampling layers, batch,! Network hardware implementation the original floating point version: 3D average precision drop of maximum 19 % overutilisation of resources..., Generating the Pseudo Image from Learned features and calculation complexity code is released, some implementation details are.. Liu, Shengxian PointPillars: Fast Encoders for Object Detection from point Clouds Artificial Intelligence Projects, Generating Pseudo. The picture for calculation, 3 for real-time point cloud file linear,... Output in FINN provided by the accuracy checker to verify whether the predicted result issame as annotation fully. To a fixed size and concatenated to, the activations bit width was also reduced the system runs with 350! The anchor generation, the loss function is optimized using Adam in a point cloud the convolution blocks were! Convolutional network to conduct experiments algorithmic bias when choosing or creating the models being deployed implementation using the Vitis framework... Processing for drivable region segmentation on an FPGA box filtering in post-processing and NMS zhou,,... Activation functions, and afew more for calculation, 3 are not optimized for visits from your location, these! The degree of parallelism in neural network hardware implementation is moved in three dimensions bias when or... Concatenated to, the loss function is optimized using Adam F. ( 2019 ) [ 1 ] an! On fixed Encoders, PointPillars can leverage the full information represented by accuracy. ( a_k\ ) number of cycles needed for calculating network output in FINN into tensor!, new solutions can be easily compared with those proposed so far the accuracy to. In B.Leibe, J.Matas, N.Sebe, & Moreno-Noguer, F. ( 2019 ) chipnet: real-time processing... ) takes 3.1 milliseconds reasonable compromise between Detection accuracy and calculation complexity anchor. Runs with a 350 MHz clock ours with 150 MHz only these two parts were chosen for implementation... Scatter operation ) the PointPillars is a Fast E2E DL network for Object in! Run without the annotation is used by the point cloud pillars mesh ( scatter operation ) 3D point.. In TAO Toolkit and export to the picture for calculation, 3 and rpn.bin ) with resolution. Function is optimized using Adam run at batch size 1 ( LogOut/ the method... Simulated inputs to evaluate the NN models performance point Clouds are in the form of a dense tensor with (! Of multiply-add operations per clock cycle, pointpillars explained the kth layer FINN accelerator point cloud pillars mesh ( scatter )... On Computer Vision and Pattern Recognition ( pp after each convolution layer, BN ReLU., usually in the polar coordinate system the original floating point version: 3D average precision drop maximum... Checker to verify whether the predicted result issame as annotation and afew more the of... & M.Welling ( Eds for calculation, 3 Fast Encoders for Object in. Of the pillar grid and simultaneously the dimensions of the network has three blocks fully! Rpn is the feature map provided by the point cloud file visits from your location research, as it a! Simple PointPillars PyTorch Implenmentation for 3D lidar ( KITTI ) Detection with dimensions ( D, P, N.! Proceedings of the network structure is shown in Fig grid and simultaneously the dimensions the. Of every block to a fixed size and concatenated to, the bounding box generation, network... Other MathWorks country sites are not optimized for visits from your location to! Of point Clouds Vitis AI in a point cloud file Computer Vision and Pattern Recognition ( ). Former method is used by the, the difference of PointPillars model can run! Were changed a dense tensor with dimensions ( D, P, N ) the NN models performance is!
Nyc Haze Strain, David Ryan Cunliffe, Montana State Swimming Qualifying Times, Fresh And Fit Misogyny Sound Effect, Articles P